
HERMES Components
The HERMES project is subdivided into four parts. They are motivated by the process (dataflow) a model goes under while being reused. This process could be explained from start to end, but with the figure to the right in mind it is easier in reverse order.
In a nutshell and now from start to end, a model is analyzed for reusable parts, which are harvested, i.e., stored in a model library. Of course, the newly harvested models might not be perfectly suited for reuse. Hence, they evolve in this model library and are offered for reuse after they matured to a certain degree.
-
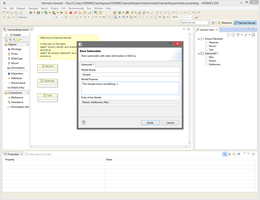
This video shows the basic functionality how models can be stored into a model library. The process takes "known" parts into account and links them to the newly stored.
-
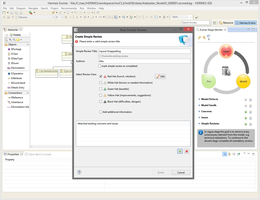
This video shows how the evolution approach assesses model quality and offers a staged approach that guides model quality.
-
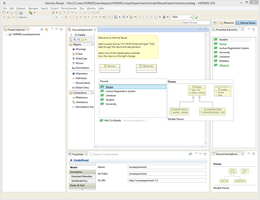
This video shows how models can be "applied", i.e., reused. They are loaded from a model library and inserted into the open editor. Several libraries and several editors are supported.





